Potřebovali bychom nějaké informace o "typických" velikostech aplikací v nějakých strojově měřitelných metrikách (SLOC, class count, nesting depth, atd.).
Aktualizace po 20 letech
Není na škodu se někdy podívat na starší příspěvky. Na srovnání je vidět, jak se celé IT rychle vyvíjí – prívě díky sdílení kódu a jeho využíváním napříč projekty.
Zatímco v roce 2002 mohl fungovat software s cca 100 000 řádky vlastního kódu (bez zapojených knihoven třetích stran), dnes by na podobnou funkcionalitu prvděpododobně stačila polovina kódu díky využití modernějších knihoven. Na druhou stranu se ale od dnešních aplikací očekává jiná úroveň uživatelského ovládání a funkcí, takže rozsah funkcí z roku 2002 by byl zcela nedostačující.
Z měření v jiném projektu máme statistiku
- 1 business funkce: průměrně 100 řádek kódu
- Můstek přenášející 1 objekt mezi dvěma systémy: cca 1000 řádek
- Jeden složitější business objekt – definice, metody: 2500 řádek
- Jeden menší modul systému – 5 business objektů, 100 souborů (zahrnuje i jazykové moduly s překlady), 50000 řádek.
Na číslech je patrné, že ačkoli se "základní" kód velikostí nijak nemění, objem kódu nutný pro naprogramování modulu zahrnuje hodně dalšího "textu", který není jenom programovým kódem.
Čísla vyházejí z cca 3 letého projektu zahrnujícího řádově 1 mil. řádků vlastního kódu. (odhad velikosti využávaných knihoven je jen přibližný, 10 – 20 mil. řádků kódu) I celý rozsah současného projektu (psáno v r. 2022) je na dnešní poměry malý, ale v r. 2002 by byl považován ze velký projekt.
Jaké metriky se u programování skutečně vyplatí sledovat
Pojem metriky kódu (code metrics) už je sám o sobě zastaralý v tom, že tvorba kódu je jen malou částí celého vývoje aplikace. To ale rozhodně neznamená, že by měřitelné veličiny ztratily svůj smysl.
Důležité metriky osvědčené pro komerční aplikace:
- Objem outsourcovaného kódu
- Objem kódu, ke kterému chybí kvalitní analýza (nidky nebyla, nebo se ztratila)
- Počet externích využávaných knihoven
- Průměrná frekvence úprav jednotlivých modulů
- Počet funkcí bez dokumentovaných všech atributů nebo návratové hodnoty (požadavek: 0)
- Počet funkcí bez přesně definované návratové hodnoty (požadavek: 0)
- Objem vlastního kódu staršího než 8 let
- Počet externích knihoven, které nemají více než 2 roky aktualizaci
- Počet externích knihoven, se kterými se v týmu nikdo nezná
- Objem interního kódu, který nemá znalého správce
- Objem kódu na jednoho odborného člena týmu
- Objem kódu, se kterým v týmu umí pracovat jen 1 pracovník
- Počet spravovaných "branches" v git
- Objem kódu, u kterého není jasné, jestli se používá
Zejména ve srovnání s metrikami uvedenými dále je patrné, že výše uvedné metriky se kódem v podstatě nezabývají. Resp. zabývají, ale ne z hlediska kódu samotného, ale z hlediska jeho správy. Na základě pomoci firmám a vlastní zkušenosti jsme přesto přesvědčeni, že jsou tyto metriky důležitější pro hodnocení zdraví aplikace, než více tradiční, a také užitečné metriky.
- Průměrný měsíční přírůstek kódu
- Procento nového kódu vzhledem ke ke kódu upravovaného
- Objem úprav, které jsou opravami vs. objem nového vývoje
- Procentuální objem komentářů (jedno z mála automaticky hodnotitelných kritérií)
- Srozumitelnost komentářů
- Množství kódu, které prošlo interní revizí
- Objem nestovaného kódu
- Počet rozhraní mezi moduly
Měření požadované standardy
Pokud je kód vyvíjen jako součást systému s vlivem na bezpečnost, vždy se na ně vztahují standardy, které měření kvality vývoje předepisují. Pro automobilový průmsysl jsou to především standardy Formel Q, VDA 6.5, ISO 26262 a Automotive SPICE. Pro jiné oblasti bude platný např. standard ISO 61508.
Zejména Formel Q je velmi konkrétní a řadu metrik přímo předepisuje. Ostatní zmiňované standardy nejdou do takových podrobností, ale ve svém jádru se všechny shodují. Důležitými metrikami jsou:
- Shoda kódu s analýzou
- Cyklomatické číslo (musí být pod 80)
- Počet možných průchodů kódem (bez započítání počtu cyklů)
- Počty skoků
- Počet funkcí, které jsou z jedné funkce volány (musí být max 5)
- Celkový počet volání fukcí (max 7)
- max počet interních proměnných funkce (max 50)
- Počet rekurzivních volání (max 0 – rekurze je zakázána)
Připomínám, že uvedné příklady se týkají kódu určeného pro provoz ve vozidle, tedy poteciálně nebo reálně s vlivem na bezpečnost. Např. zákaz rekurze by v obecném případě nedával smysl.
Původní odpověď
S tím dotazem máme jeden zásadní problém: Co je to typická aplikace? I když aplikace není postavená na SOA architektuře, je každá "rozumná aplikace" postavená z desítek modulů a většinou i samostatných komponent. Pokud jde o produktovou aplikaci, pak jsou moduly stavěné tak, aby bylo možné nasadit ty, které mají pro zákazníka smysl, takže 2 konkrétní aplikace jednoho produktu se mohou lišit v počtu nasazených tříd třeba i několikanásobně.
Relativně malý procesní OSS systém pro telekomunikačního operátora má cca 80 000 vlastních řádek kódu, ale využívá knihovny s dalšími cca 300 000 řádkami.
Počty třídy jsou v řádu stovek (580 podle posledního měření). Nesting Depth jsme přestali sledovat, protože stačí pár rozhodovacích metod typu
if (a) {?}
else if (b) {?}
...
else if (z) {?}
else error
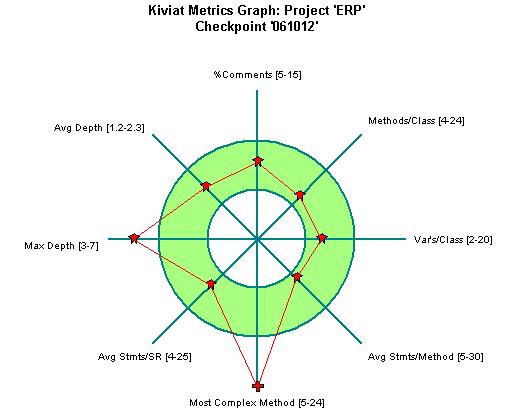
které vytvoří hloubku klidně 30 – 50 (měli jsme i 120, to po rozdělení kleslo na 20). I v průměru takové funkce hodnotu dost křiví, ale průměr byl někde na 8. Chtělo by to počítat medián, ale zase automatické nástroje nedělají. Když jsme vyřadili tyto výjimky z pravidla, dostali jsme se na 8. Něco z toho ukáže Kiviat Graf projektu (viz obrázek).
Uvedená aplikace je nativní Windows aplikace (tlustý klient) s aplikačním serverem. Totéž postavené na SOA architektuře a přístupu přes internet má cca 3x tolik řádek kódu, ale složitost kódu je skoro stejná. (Tato složitost nic nevypovídá o složitosti správy a údržby.)